 Ankit RanaCTO, Polestar Analytics
Ankit RanaCTO, Polestar Analytics
Sign up to receive latest insights & updates in technology, AI & data analytics, data science, & innovations from Polestar Analytics.
With every passing day, organizations around the world find themselves facing challenges around data management - much more than they did ever before. Since the use of data started in the 1980s a lot has changed; especially with the onset of cloud computing which has brought about massive changes in the way data is used, consumed and understood.
Today, volumes of data are being generated every second; and finding storage solutions for these massive volumes is of utmost importance. When it comes to managing data, data managers, and professionals consider using either data warehouses or data lakes as a repository.
So, what do these terms mean, what distinguishes them from one another, and what is the better solution for your organization?
Here, we take a deep dive into the similarities and differences between data warehouses and data lakes, with the intent to solve some questions for companies given the constraints that they face with respect to their environment and budgets.
A data lake is a system or repository of data stored in an unstructured way and in its natural/raw format; i.e., it is not processed or analyzed. A data lake allows organizations to store heaps of diverse datasets without having to build a model first.
It is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning.
Think of it this way, a data lake can be understood as a large body of water, say a lake in its natural state. The data lake is created with data streaming in from various sources, and then, various users can come to the lake to examine it and take samples.
A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video). It is especially useful when data managers are looking for ways to capture and store data from a variety of sources in various formats. In a lot of instances, data lakes are considered cost-effective and used with the intent to store data for exploratory analysis.
A data warehouse, on the other hand, brings all your data together and stores it in an organized/ structured manner. It helps consolidate data in one place with the intent of deriving real business insights which can then be used to make better business decisions - it essentially helps you derive value from the data.
Once used for the data has been identified it is then loaded into a data warehouse, which then enables organizations to get insights through analytical dashboards, operational reports, and/ or advanced analytics.
Data warehousing simply enhances the quality of business intelligence, so that executives no longer need to make business decisions based on limited/ constrained data or based on their gut.
With all kinds of data stored in one place, data warehouses allow organizations to quickly make informed decisions on key initiatives.
Off late, there has been an increase in conversations on both data warehouses and data lakes, with people trying to understand each’s benefits, and even on how both share the enterprise stage. It's not about pitting one against the other, rather about understanding how both can work in tandem.
SUGGESTED READING: DATA LAKES VS DATA WAREHOUSE! WHAT ARE THE DIFFERENCES?
Data Sources: Data sources are where original data, a variety of internal and external sources, reside. It can either be operational data sources like ERP, CRM, etc. or social media data like website hits, content popularity, etc. or even third party data like demographics, surveys, census, etc. or even non-structured data like images, videos, etc.
Raw/Landing Layer: Data is extracted from different source systems and stored in a raw format in the landing layer of the data lake. The landing layer tags the data for the source system.
Standardized Layer: As data comes in different formats (relational, JSON, Binary, etc.) data needs to be standardized into the rows and/or columns format. This layer also transforms the data and applies business logic.
Curated Layer: This layer is created as per business requirements and it can have data marts for reporting and analytics. It can have de-normalized data for data scientists, depending upon who is accessing the curated layer.
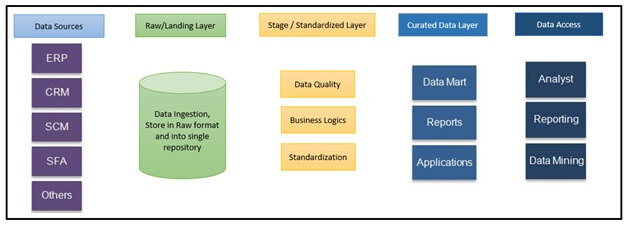
Different from data warehouses, data lake follows the ELT or extract load transform approach. Here’s how it works:
Data Extraction and Loading: The extraction activity of the source data includes data extraction routines that read the data, and move it to a landing area in a format. The data extraction process is subdivided into:
Data Transformation: This includes data cleansing, data standardization, business logic, etc.
The quality (perfection, validity, and accuracy) of the data should be dimensioned and informed so that the decision-makers can evaluate the reliability of the data, only then decide what measures to take.
The data coming from different sources may come as different formats that are standardized into the tabular format of rows and columns e.g. converting JSON data into tables. Business logic is applied as per requirements. The data is stored in a curated layer from which data is accessible to all as per requirements.
Think of data architecture like a shepherd’s pie, or a lasagna - with layers. Each layer plays a role, in this case - in converting raw data into valuable data ready to be used for consumption - analysis and business intelligence. For the raw data to become valuable, it has to go through a process of layering, sorting, structuring, and cleaning, only then does the most relevant data make it to the top. A data warehouse essentially makes this happen.
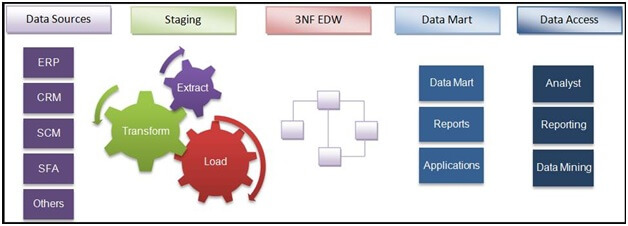
Data Sources: Data Sources are where original data, a variety of internal and external sources, reside. It can either be operational data sources like ERP, CRM, etc. or social media data like website hits, content popularity, etc. or even third party data like demographics, surveys, census, etc. or even non-structured data like images, videos, etc.
Staging Layer: Data needs to be extracted from different source systems and then lands on to the staging layer. In EDW the staging layer is Truncate Load Staging Layer where incremental data needs to be extracted from the source system.
Transformation: Data needs to be transformed according to data model and business logic. It's important to note that transformation layers may vary from system to system and requirement to requirement.
Loading: Transformed data needs to be then loaded into EDW as per best practices and requirements.
Data Marts: Data Marts are created on the top of EDW to match the reporting requirements and to get the best-in-class performance while reporting.
The best practices or decisions to be made for data warehouses:
Data warehouses follow the ETL or Extract transform load approach. Here’s how it works:
1). Data Extraction: The extraction activity of the source data includes data extraction routines that read the data, convert this data into an intermediate schema, and move it to an area, which is a temporary working area in which data is maintained in intermediate schemas. The data extraction process is subdivided into:
2). Data Transformation: This is one of the most important processes in the ETL. Data transformation also includes data cleansing. The quality (perfection, validity, and accuracy) of the data warehouse data should be dimensioned and informed so that the decision-makers can evaluate the reliability of the data, and only then decide what measures to take.
The most common types of dirt data are:
The other data transformations include:
3). Data Loading: After the data transformation is carried out the loading process comes next - wherein the data is placed on the data warehouse server. Once the data is in EDW then specific data marts are created as per the reporting or business requirements.
Data lakes and data warehouses are two sides of the same coin - they are different tools, used for different purposes - depending on what an organization is trying to achieve. Data lakes retain all data, while data warehouses retain cleansed, processed and structured data.
Data lakes are cost effective, relatively easy to make changes to, while it is more difficult to make changes to the structure of a data warehouse, simply because of the number of layers and processes attached to it.
Ultimately, as enterprise data becomes more diverse, organizations have the option of choosing what might work best for them, and understand the functional aspects of both warehouses and lakes and work towards a model that gets the best of both for them.
The fast-pace at which companies are adopting a data-first strategy to lead their digital transformation is driven based on data analytics. Competent data methods are coming into play to fix the missing pieces for organizations facing constraints, biases and failures.
In the case of implementing data warehouses and data lakes, each has the ability to help transform operational, historical and even real-time data to improve efficiency, enhance better business performance and eventually enhance customer experience.
While a lot of organizations are still struggling to experiment with data warehouses and data lakes, it has become a standard requirement for organizations to adapt to the ever-evolving face of data analytics.
Overall, there is a lot of optimism about analytics in the near future, where we will see organizations across all spectrums and sizes incorporating it into their daily business operations.
At the end of the day, at Polestar we hope to bring the power of data to organizations across industries helping them analyze billions of data points and data sets to provide real-time insights, and enabling them to make critical decisions to grow their business.
About Author

CTO, Polestar Analytics Ex- Deloitte
There are thousands of hidden stories within data, how you make these stories meaningful is with analytics.
Related Blog
 Shriya Kaushik
Shriya Kaushik
